Posted by Tom.Capper
Back in September last year, I was lucky enough to see Rand speak at MozCon. His talk was about link building and the main types of strategy that he saw as still being relevant and effective today. During his introduction, he said something that really got me thinking, about how the whole purpose of links and PageRank had been to approximate traffic.

Essentially, back in the late '90s, links were a much bigger part of how we experienced the web — think of hubs like Excite, AOL, and Yahoo. Google’s big innovation was to realize that, because people navigated the web by clicking on links, they could approximate the relative popularity of pages by looking at those links.
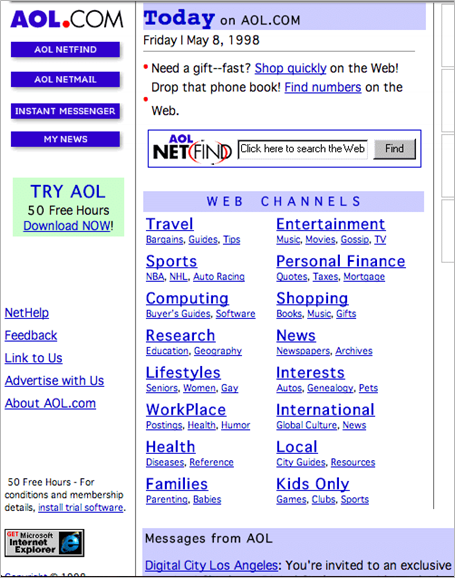
So many links, such little time.
Rand pointed out that, given all the information at their disposal in the present day — as an Internet Service Provider, a search engine, a browser, an operating system, and so on — Google could now far more accurately model whether a link drives traffic, so you shouldn’t aim to build links that don’t drive traffic. This is a pretty big step forward from the link-building tactics of old, but it occurred to me that it it probably doesn’t go far enough.
If Google has enough data to figure out which links are genuinely driving traffic, why bother with links at all? The whole point was to figure out which sites and pages were popular, and they can now answer that question directly. (It’s worth noting that there’s a dichotomy between “popular” and “trustworthy” that I don’t want to get too stuck into, but which isn’t too big a deal here given that both can be inferred from either link-based data sources, or from non-link-based data sources — for example, SERP click-through rate might correlate well with “trustworthy,” while “search volume” might correlate well with “popular”).
However, there’s plenty of evidence out there suggesting that Google is in fact still making significant use of links as a ranking factor, so I decided to set out to challenge the data on both sides of that argument. The end result of that research is this post.
The horse's mouth
One reasonably authoritative source on matters relating to Google is Google themselves. Google has been fairly unequivocal, even in recent times, that links are still a big deal. For example:
- March 2016: Google Senior Search Quality Strategist Andrey Lipattsev confirms that content and links are the first and second greatest ranking factors. (The full quote is: “Yes; I can tell you what they [the number 1 and 2 ranking factors] are. It’s content, and links pointing to your site.”)
- April 2014: Matt Cutts confirms that Google has tested search quality without links, and found it to be inferior.
- October 2016: Gary Illyes implies that text links continue to be valuable while playing down the concept of Domain Authority.
Then, of course, there’s their continued focus on unnatural backlinks and so on — none of which would be necessary in a world where links are not a ranking factor.
However, I’d argue that this doesn’t indicate the end of our discussion before it’s even begun. Firstly, Google has a great track record of giving out dodgy SEO advice. Consider HTTPS migrations pre-2016. Will Critchlow talked at SearchLove San Diego about how Google’s algorithms are at a level of complexity and opaqueness where they’re no longer even trying to understand them themselves — and of course there are numerous stories of unintentional behaviors from machine learning algorithms out in the wild.
Third-party correlation studies
It’s not difficult to put together your own data and show a correlation between link-based metrics and rankings. Take, for example:
- Moz’s most recent study in 2015, showing strong relationships between link-based factors and rankings across the board.
- This more recent study by Stone Temple Consulting.
However, these studies fall into significant issues with correlation vs. causation.
There are three main mechanisms which could explain the relationships that they show:
- Getting more links causes sites to rank higher (yay!)
- Ranking higher causes sites to get more links
- Some third factor, such as brand awareness, is related to both links and rankings, causing them to be correlated with each other despite the absence of a direct causal relationship
I’ve yet to see any correlation study that addresses these very serious shortcomings, or even particularly acknowledges them. Indeed, I’m not sure that it would even be possible to do so given the available data, but this does show that as an industry we need to apply some critical thinking to the advice that we’re consuming.
However, earlier this year I did write up some research of my own here on the Moz Blog, demonstrating that brand awareness could in fact be a more useful factor than links for predicting rankings.

The problem with this study was that it showed a relationship that was concrete (i.e. extremely statistically significant), but that was surprisingly lacking in explanatory power. Indeed, I discussed in that post how I’d ended up with a correlation that was far lower than Moz’s for Domain Authority.
Fortunately, Malcolm Slade recently discussed some of his very similar research at BrightonSEO, in which he finds similar broad correlations to myself between brand factors and rankings, but far, far stronger correlations for certain types of query, and especially big, high-volume, highly competitive head terms.
So what can we conclude overall from these third-party studies? Two main things:
- We should take with a large pinch of salt any study that does not address the possibilities of reverse causation, or a jointly-causing third factor.
- Links can add very little explanatory power to a rankings prediction model based on branded search volume, at least at a domain level.
The real world: Why do rankings change?
At the end of the day, we’re interested in whether links are a ranking factor because we’re interested in whether we should be trying to use them to improve the rankings of our sites, or our clients’ sites.
Fluctuation
The first example I want to look at here is this graph, showing UK rankings for the keyword “flowers” from May to December last year:

The fact is that our traditional understanding of ranking changes — which breaks down into links, on-site, and algorithm changes — cannot explain this degree of rapid fluctuation. If you don’t believe me, the above data is available publicly through platforms like SEMRush and Searchmetrics, so try to dig into it yourself and see if there’s any external explanation.
This level and frequency of fluctuation is increasingly common for hotly contested terms, and it shows a tendency by Google to continuously iterate and optimize — just as marketers do when they’re optimizing a paid search advert, or a landing page, or an email campaign.
What is Google optimizing for?

The above slide is from Larry Kim’s presentation at SearchLove San Diego, and it shows how the highest SERP positions are gaining click-through rate over time, despite all the changes in Google Search (such as increased non-organic results) that ought to drive the opposite.
Larry’s suggestion is that this is a symptom of Google’s procedural optimization — not of the algorithm, but by the algorithm and of results. This certainly fits in with everything we’ve seen.
Successful link building
However, at the other end of the scale, we get examples like this:

The above graph (courtesy of STAT) shows rankings for the commercial keywords for Fleximize.com during a Distilled creative campaign. This is a particularly interesting example for two reasons:
- Fleximize started off as a domain with relatively little equity, meaning that changes were measurable, and that there were fairly easy gains to be made
- Nothing happened with the first two pieces (1, 2), even though they scored high-quality coverage and were seemingly very comparable to the third (3).
It seems that links did eventually move the needle here, and massively so, but the mechanisms at work are highly opaque.
The above two examples — “Flowers” and Fleximize — are just two real-world examples of ranking changes. I’ve picked one that seems obviously link-driven but a little strange, and one that shows how volatile things are for more competitive terms. I’m sure there are countless massive folders out there full of case studies that show links moving rankings — but the point is that it can happen, yet it isn’t always as simple as it seems.
How do we explain all of this?
A lot of the evidence I’ve gone through above is contradictory. Links are correlated with rankings, and Google says they’re important, and sometimes they clearly move the needle, but on the other hand brand awareness seems to explain away most of their statistical usefulness, and Google’s operating with more subtle methods in the data-rich top end.
My favored explanation right now to explain how this fit together is this:
- There are two tiers — probably fuzzily separated.
- At the top end, user signals — and factors that Google’s algorithms associate with user signals — are everything. For competitive queries with lots of search volume, links don’t tell Google anything it couldn’t figure out anyway, and links don’t help with the final refinement of fine-grained ordering.
- However, links may still be a big part of how you qualify for that competition in the top end.
This is very much a work in progress, however, and I’d love to see other people’s thoughts, and especially their fresh research. Let me know what you think in the comments below.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
Source: Moz Blog