 |
In our last installment of Unwrapping the Secrets of SEO, my colleague Holly Miller outlined the steps to employ in choosing good online topics at the right time, and in good SEO shape. Now it’s time to make sure that those topics you’re writing on will be optimized equally well for users and search engines. It’s time to talk about semantic topic optimization!

Intro to Content Optimization
As an online marketer, SEO or content writer, your ultimate goal is to make sure whatever you create for online audiences will perform as expected. That could come in the form of user signals, higher rankings, social shares – or conversions. The goal of content optimization is exactly that – to make sure your content connects in moments that matter when users are looking for information via search engines. For that to happen, it needs to be deemed as relevant as possible by search engines (and thus users) for a specific topic. Ultimately, optimizing your content is better served by understanding that what you’re really trying to do is increase content relevance rather than optimize it.
This general concept of increasing content relevance is something that is not only fun to geek out on from an SEO’s perspective, but is also extremely useful for helping content writers understand which subtopics should be included within topics.
In order to fully trust data that will help us increase our content relevance, let’s dive under the hood for a view of how Google understands relevance in content.
A Brief History of Keyword Density
Before the days of artificial intelligence, machine learning and all those fancy algorithms, Google rated page quality mainly based on two factors: links and keyword density. For SEOs like me, this was actually quite fun. Search engine optimization in the “old days” of a few years ago used to be much more tactic-based than strategy-based.
Nowadays, it’s a different ballgame. Google and other search engines have gotten smarter and no longer judge relevancy based simply on a few links or a few on-page keywords.
OK, if you’re not optimizing for a keyword using keyword density, how do you optimize for a topic? The next two concepts may seem complicated at first, but should be easy to understand.
Latent Semantic Indexing
The first is Latent Semantic Indexing, or LSI. The way Google uses LSI is actually pretty simple. A mathematical formula defines the proximity and relationship between terms in a piece of content. Search engines will crawl a webpage and, based on your webpage title or main topic, the most common words and phrases are grouped and identified as the core topic keywords of the page. If the terms that the search engine found on your page are relevant terms, it would expect to find related terms such as “automobiles,” “second hand,” “auction,” etc.
For most of you, all this should sound very familiar. LSI is simply a co-occurrence-based method where search engines look for terms that naturally occur in conjunction with other terms. Here’s more info on LSI from a post I wrote a few months ago.
To TF*IDF or Not to TF*IDF
If you’re looking to go deeper, TF*IDF, or Term Frequency * Inverted Document Frequency, is the more advanced formula. Portent.com writes this about TF*IDF:
“..It is NOT OK to leave out the mother of all information retrieval algorithms, TF-IDF, known affectionately to search geeks as Term Frequency-Inverse Document Frequency.
Introduced in the 1970s, this primary ranking algorithm uses the presence, number of occurrences, and locations of occurrence to produce a statistical weight on the importance of a particular term in the document. It includes a normalization feature to prevent long boring documents from taking up residence in search results due to the shear nature of their girth.”
Though you can see it’s an older concept, it still remains very relevant. Similar to LSI, TF*IDF looks at specific keywords and tries to understand the relationship between each. However, it goes a step further by giving specific weighting to each term.
Let’s say you’re trying to understand which words and phrases are relevant to the topic of used cars. We’d set the formula to look at the top 20 ranking pages. TF*IDF will work in two ways:
- TF (Term Frequency): a crawler will look at each of the words on each webpage and determine the term frequency (keyword density) of each of those words:

This would be repeated for page 2, page 3, etc.
- IDF (Inverted Document Frequency): The crawler will then look at all these words and identify how many documents (out of the 20 analyzed) these words are present in.
- It’s repeated for page 2, page 3, etc…
- TF*IDF: Once these two items are put together, a simple logarithm is calculated and returns a score (weight) for each term analyzed.
Second-hand automobile: TF*IDF = 0.8
Used automobile: TF*IDF = 0.6
What makes this method amazing is that it actually takes the guesswork out of trying to understand which words and thus topics should be used in conjunction with the core topic of your text. You are then able to analyze which keywords hold the most weight and therefore are more important to the topic you are writing about.
And by the way – Google talks about TF*IDF in a few of its search patents:
If you didn’t think it was important to understand before. I hope you do now.
Delving into Entity Types
Now let’s talk about entity types. We’ve seen a sample of how Google understands the most important terms for a specific topic ; Google also understands the categorization of words. Let’s use this article as an example. The headline reads “Trump threatens German carmakers with 35 percent US import tariff,” giving a good overview of what you’d read in the piece. In brief, the article says BMW, GM’s Vauxhall brand and others are being put on notice by President Trump to produce more in the U.S. He cites Daimler and Renaul-Nissan for assembling products in Agauscalientes, Mexico, and threatens them with an import tariff if they don’t invest more in US-based manufacturing. Below, I use the entity search tool from IBM’s Watson to see how a machine-learning algorithm defines content relevance and how each word is classified into a specific entity type:
Here’s an additional resource regarding how Google clusters entities:
What does this mean? Search engines, especially those smart enough to use machine learning, look at EVERY word in your text document, and will weigh and classify them. To beat the competition, you’ll need to understand all these concepts and make sure everything on your page is properly optimized.
Content Quality vs. Content Structure
Now that we’ve talked about making our content relevant in terms of quality, let’s look at how our content is relevant in terms of structure.
One huge paradigm that many SEOs (used to) get wrong is simply spitting out content (even well optimized) anywhere on the page and hoping it’ll rank (I’m talking about you foils especially in e-commerce). Let’s have a look at two pieces of content:
Version 1:
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquet. Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac. Vivamus quis ex quis arcu malesuada rhoncus vel eget ex. Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum. Nunc finibus risus id odio vulputate, at pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.“
Version 2:
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquot:
- Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac.
- Vivamus quis ex quis arcu malesuada rhoncus vel eget ex.
- Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum.
Nunc finibus risus id odio vulputate, at pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.”
Version 2 looks better, right?
This is not just something that will help overall user signals (lower bounce rate, higher time on page, which hopefully will lead to increased pages per sessions) – but will help rankings as search engines understand various CSS elements and therefore how a page is laid out.
Getting Real with These Concepts
Let’s say your core topic is “buying a used car” and you’re trying to understand which subtopics to write about: Should I talk about the process? Tips? Buying an out of state car?
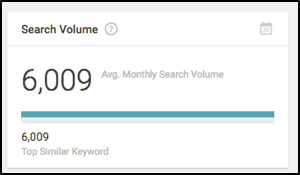
The first step is understand the market as best you can in any given moment. Using the Searchmetrics Content Experience agile content development platform, we’re able to quickly identify a few high-level items, including search volume, seasonality, similar keywords & search integrations to guide our topics:


The next step in the Searchmetrics Content Experience is working with the Topic Explorer to understand which topics are resonating in the marketplace, and why:
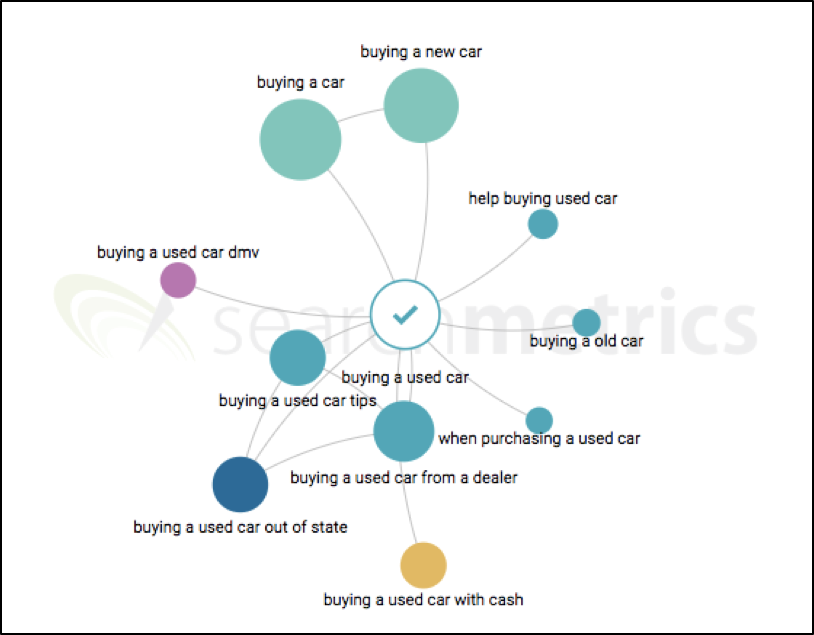
Thanks to the Searchmetrics topic graph we’re able to quickly identify core topics that are semantically close to the main topic of “buying a used car.” Interestingly, we’ll notice that many people are interested in knowing how to buy a used car with cash, or buying a used car out of state, or from a dealer. Since our analysis can include up to five core topics, we’ll include the ones with the higher search volume.
By selecting a few of these other topics our total search volume increases to around 7,000+
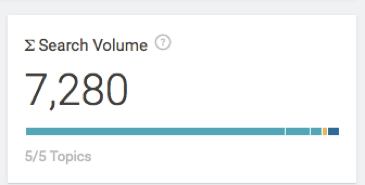
That done, we can start writing!
Applying Keywords with Agile Content Development
Once we’re ready to write, let’s take a gander at what you’d see on the left in the Searchmetrics Content Experience’s editor module. Before even writing anything, we’ll notice a few very interesting things, mainly which keywords (essentially subtopics) to write about, and the frequency recommended for each to rank well in search results.
Remember all these content concepts earlier in the article? Take a look to see where most of these keyword recommendations are calculated.
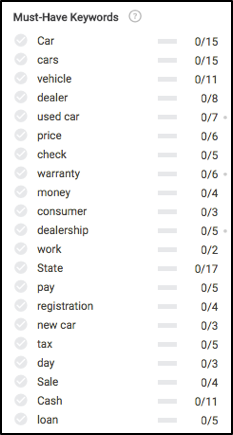
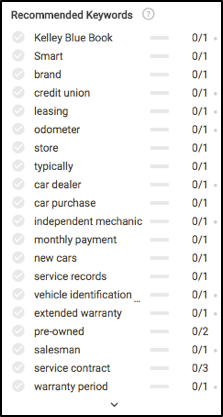
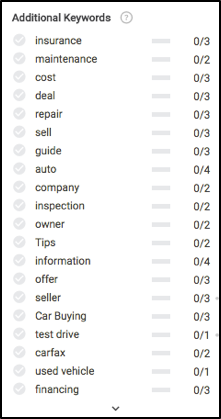
Based on the data above, in order to make sure our content is fully relevant we need to write about insurance, maintenance, the test drive process, warranty, registration, financing and a few others.
Once we start writing, this is where the fun starts:
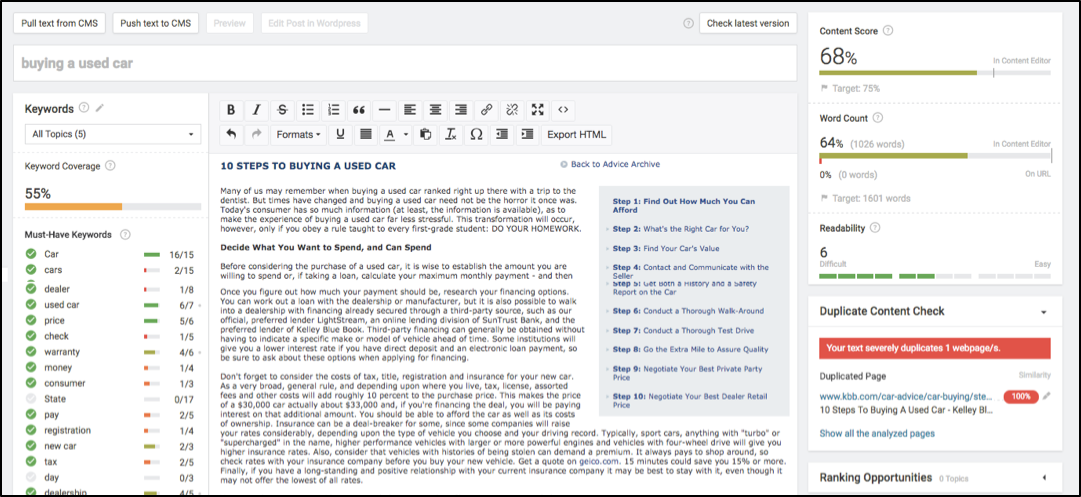
Searchmetrics Content Experience
I can use the tool to take a data-driven approach to holistically writing content, get scored on how readable and well structured it is and even see in the console where duplicated content from other sites might cause me problems in ranking.
If you’re looking to geek out a bit more and get into the data, we will break down TF*IDF and other data driven recommendations.
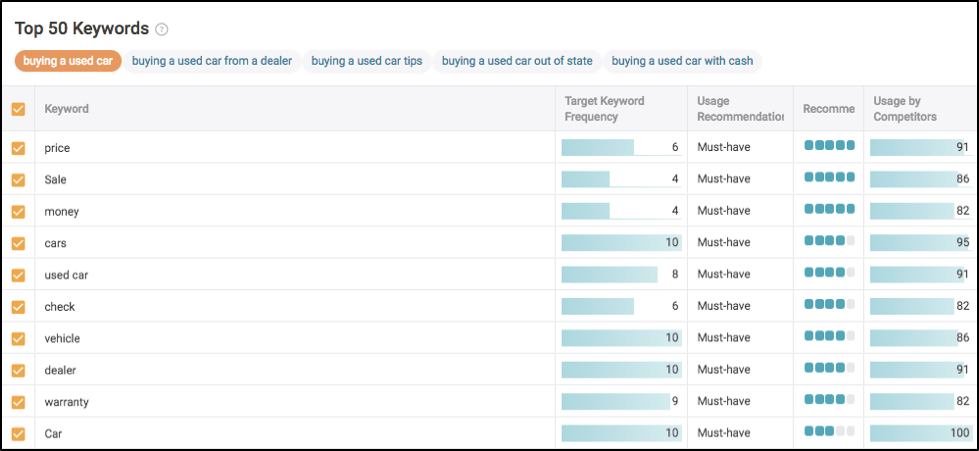
Top Keywords in the Searchmetrics Content Experience
Finally, you track impact. Make sure you are tracking all 5 core topics to see which performs better in terms of rankings, traffic and user signals.
A reminder: the old “publish and forget” mentality is no more. You should “publish and recycle” to make sure your content is always optimized and up-to-date.
Unwrapping the Secrets of SEO
Understanding the basics of semantic content optimization is vital. You do not need to be technical. You do not need to be a data scientist. You simply need to pay attention and be curious. Once you’ve understood the value of semantically optimizing your content, data-centric writing will not just be more fun, but will start to make much more sense.
Sebastien helps Fortune 500 companies better optimize their web presence as an in-house SEO Specialist at Searchmetrics. With experiences leading SEO efforts for brands abroad (e.g. InterNations.org) and helping Silicon Valley startups kick start their search efforts, he loves digging into analytics data hands-on to interpret and shape the story it tells.
Show all articles from Sebastien Edgar.
Source: Searchmetrics